Composing Programs学习笔记
1 Python检验函数的方法
1.使用assert声明方法
# define a function to test
def fib(x):
if x==0:
return 0
elif x==1:
return 1
else:
return fib(x-1)+fib(x-2)
# define a test function
def fib_test():
assert fib(2) == 1 # The 2nd Fibonacci number should be 1
assert fib(3) == 1 # The 3rd Fibonacci number should be 1
assert fib(50) == 7778742049 # Error at the 50th Fibonacci number
# execute test
fib_test(2)
fib_test()函数会先执行fib()函数,然后与assert命令的指标进行对比,如果不符就会报错。
2.使用run_docstring_examples函数
def sum_naturals(n):
"""Return the sum of the first n natural numbers.
>>> sum_naturals(10)
55
>>> sum_naturals(100)
5050
"""
total, k = 0, 1
while k <= n:
total, k = total + k, k + 1
return total
from doctest import run_docstring_examples
run_docstring_examples(sum_naturals,globals(),True)
函数sum_naturals()在声明时使用三个引号提供了一份简单的说明。在编译器中执行help()函数皆可获得这段说明(按Q退出)。同时,这份说明也指出了特定之下的输出值。利用run_docstring_examples函数可以自动完成检验,并输出检验结果。例如,
Trying:
sum_naturals(10)
Expecting:
55
ok
Trying:
sum_naturals(100)
Expecting:
5050
ok
2 高阶函数
Python允许定义一个函数返回一个代数式,同样的,也可以定义一个函数去引用其他函数。
引用其他函数的函数就是高阶函数。
Lexical scope(词法定界)
一个函数只能引用有限范围内的函数。其范围包括:定义本函数的同级框架,以及父级框架。
TechTarget中国原创:词法定界(lexical scoping,有时候叫静态域)是许多编程语言约定使用的,变量只能在这套范围(按功能排列)内被一些已经定义了的代码段中调用(引用)。当被编译之后,这些范围将确定下来。变量定义用这种格式的有时候叫做私有变量。相反的,还有动态域(dynamic scoping)。动态域产生可以在定义变量的代码段外调用的变量。这样定义的变量也叫公共变量。
一个栗子
科学计算里常用到的 迭代法 可以提炼为一个calculate()函数包含有三个子函数:猜测函数guess()、更新函数update()、检验函数check()。
# original version
def improve(update, close, guess=default):
while not close(guess):
guess = update(guess)
return guess
# or self-defined
def calculate(x, close_enough):
y = guess(x)
while check(y) > close_enough:
y = update(y);
return y
Currying(柯里化)
来自维基百科
在计算机科学中,柯里化(英语:Currying),又译为卡瑞化或加里化,是把接受多个参数的函数变换成接受一个单一参数(最初函数的第一个参数)的函数,并且返回接受余下的参数而且返回结果的新函数的技术。这个技术由Christopher Strachey以逻辑学家哈斯凯尔·加里命名的,尽管它是Moses Schönfinkel和戈特洛布·弗雷格发明的。
在直觉上,柯里化声称“如果你固定某些参数,你将得到接受余下参数的一个函数”。所以对于有两个变量的函数y^x,如果固定了y=2,则得到有一个变量的函数2^x。
在理论计算机科学中,柯里化提供了在简单的理论模型中,比如:只接受一个单一参数的lambda演算中,研究带有多个参数的函数的方式。
函数柯里化的对偶是Uncurrying,一种使用匿名单参数函数来实现多参数函数的方法。例如:var foo = function(a) { return function(b) { return a * a + b * b; } }这样调用上述函数:(foo(3))(4),或直接foo(3)(4)。
Python允许一个函数赋予多个独立的参数。例如,
def h(x,y):
return x**2+y/3
# define a currying function
def f(x):
def g(y):
return h(x,y**y)
return g
print f(2)(3)
运行后返回:13
Lambda表达式
Lambda表达式允许表达式的嵌套,而无需单独命名引用。
引自原文 lambda x : f(g(x)) “A function that takes x and returns f(g(x))” 但是Lambda的多级嵌套虽然简洁,但不易于程序员的理解。例如:
compose1 = lambda f,g: lambda x: f(g(x))
一级函数
一级函数可以是:
- 指定有名称
- 可以作为函数参数进行传递
- 可以作为函数运行结果返回
- 可以包含在数据结构当中(data structures)
函数修饰符(Function Decorators)
>>> @trace
def triple(x):
return 3 * x
>>> triple(12)
-> <function triple at 0x102a39848> ( 12 )
36
@trace表达式提示编译器对下面定义的函数的运算过程进行跟踪,上例等同于
>>> def triple(x):
return 3 * x
>>> triple = trace(triple)
更多有关函数修饰符的只是可以看这里
3 数据抽象
数据抽象(Data Abstraction)
The general technique of isolating the parts of a program that deal with how data are represented from the parts that deal with how data are manipulated is a powerful design methodology called data abstraction.
把数据的形式和处理分离
抽象隔离(Abstraction Barriers)
An abstraction barrier violation occurs whenever a part of the program that can use a higher level function instead uses a function in a lower level.
当函数运行时,本应调用高级别子函数却使用低级别子函数时,即遇到抽象隔离。
4 序列
分解序列(sequence unpacking)
The pattern of binding multiple names to multiple values in a fixed-length sequence。
序列中各值赋予不同变量名。
>>> pairs = [[1, 2], [2, 2], [2, 3], [4, 4]]
>>> same_count = 0
如果执行下列代码:
>>> for x, y in pairs:
if x == y:
same_count = same_count + 1
就可以得到:
>>> same_count
2
列表推导式(list comprehension)
An expression that can performs such a sequence processing operation which can be expressed by evaluating a fixed expression for each element in a sequence and collecting the resulting values in a result sequence.
一行代码直接完成对列表的便利操作并返回值。
例如,
>>> odds = [1, 3, 5, 7, 9]
>>> [x+1 for x in odds]
[2, 4, 6, 8, 10]
# Another Example
>>> [x for x in odds if 25 % x == 0]
[1, 5]
通式:
[<map expression> for <name> in <sequence expression> if <filter expression>]
更多见这里。
列表推导式的效果也可以用高阶函数的方式来达到,但前者更为常见(个人觉得前者更利于理解)。
数据类型的闭合型
In general, a method for combining data values has a closure property if the result of combination can itself be combined using the same method.
例如,列表自身可以组成列表的元素。
其它
5 可变数据
-
Python3可以使用
nonlocal声明父级框架的变量 -
Python中可以使用字典将多个函数绑定在同一级
def account(initial_balance):
def deposit(amount):
dispatch["balance"] += amount
return dispatch["balance"]
def withdraw(amount):
if amount > dispatch["balance"]:
return "Insufficient funds"
dispatch["balance"] -= amount
return dispatch["balance"]
dispatch = {"deposit": deposit,
"withdraw": withdraw,
"balance": initial_balance}
return dispatch
def withdraw(account, amount):
return account["withdraw"](amount)
def deposit(account, amount):
return account["deposit"](amount)
def check_balance(account):
return account["balance"]
a = account(20)
deposit(a, 5)
withdraw(a, 17)
print(check_balance(a))
6 面向对象
类的定义方法
class Account:
def __init__(self, account_holder):
#必须有`__init__`函数,该函数无需return
self.balance = 0
self.holder = account_holder
def deposit(self, amount):
self.balance = self.balance + amount
return self.balance
def withdraw(self, amount):
if amount > self.balance:
return "Insufficient funds"
self.balance = self.balance - amount
return self.balance
子类的定义
class CheckingAccount(Account):
"""A bank account that charges for withdrawals."""
withdraw_charge = 1
interest = 0.01
def withdraw(self, amount):
return Account.withdraw(self, amount + self.withdraw_charge)
class SavingsAccount(Account):
deposit_charge = 2
def deposit(self, amount):
return Account.deposit(self, amount - self.deposit_charge)
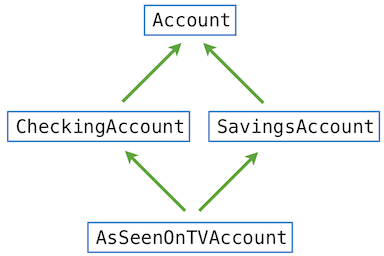
多重继承
python允许多重继承。 多重继承示意图
{kind=link}
class AsSeenOnTVAccount(CheckingAccount, SavingsAccount):
def __init__(self, account_holder):
self.holder = account_holder
self.balance = 1
7 类与实例
定义实例
一个实例本质上是一个字典,里面包含的是:“方法名”-“函数”对。
def make_instance(cls):
"""Return a new object instance, which is a dispatch dictionary."""
def get_value(name):
if name in attributes:
return attributes[name]
else:
value = cls["get"](name)
return bind_method(value, instance)
def set_value(name, value):
attributes[name] = value
attributes = {}
instance = {"get": get_value, "set": set_value}
return instance
def bind_method(value, instance):
"""Return a bound method if value is callable, or value otherwise."""
if callable(value):
def method(*args):
return value(instance, *args)
return method
else:
return value
定义类
def make_class(attributes, base_class=None):
"""Return a new class, which is a dispatch dictionary."""
def get_value(name):
if name in attributes:
return attributes[name]
elif base_class is not None:
return base_class["get"](name)
def set_value(name, value):
attributes[name] = value
def new(*args):
return init_instance(cls, *args)
cls = {"get": get_value, "set": set_value, "new": new}
return cls
def init_instance(cls, *args):
"""Return a new object with type cls, initialized with args."""
instance = make_instance(cls)
init = cls["get"]("__init__")
if init:
init(instance, *args)
return instance
栗子
def make_account_class():
"""Return the Account class, which has deposit and withdraw methods."""
interest = 0.02
def __init__(self, account_holder):
self["set"]("holder", account_holder)
self["set"]("balance", 0)
def deposit(self, amount):
"""Increase the account balance by amount and return the new balance."""
new_balance = self["get"]("balance") + amount
self["set"]("balance", new_balance)
return self["get"]("balance")
def withdraw(self, amount):
"""Decrease the account balance by amount and return the new balance."""
balance = self["get"]("balance")
if amount > balance:
return "Insufficient funds"
self["set"]("balance", balance - amount)
return self["get"]("balance")
return make_class(locals())
最后一句locals()返回一个当前框架下的字典。
Account类可使用下句生成:
>>> Account = make_account_class()
子类关于继承的实现:
def make_checking_account_class():
"""Return the CheckingAccount class, which imposes a $1 withdrawal fee."""
interest = 0.01
withdraw_fee = 1
def withdraw(self, amount):
fee = self["get"]("withdraw_fee")
return Account["get"]("withdraw")(self, amount + fee)
return make_class(locals(), Account)
>>> CheckingAccount = make_checking_account_class() #子类的生成
>>> jack_acct = CheckingAccount["new"]("Spock") #子类实例的生成
>>> jack_acct["get"]("interest") #子类实例的方法调用
0.01
8 try: except语句
try:
<try suite> # always excecute
except <exception class> as <name>: # <exception class> can be subclass of Exception Class
<except suite> # excecuted when excecuting <try suite> meets errors
栗子
>>> try:
x = 1/0
except ZeroDivisionError as e:
print("handling a", type(e))
x = 0
handling a <class "ZeroDivisionError">
>>> x
0
9 迭代
Python中自定义迭代类型,需要包含自定义的__next__方法。__next__方法能够返回迭代类型的下一项,并在迭代结束时提示编译器:StopIteration。
# define a new iteration class
>>> class LetterIter:
"""An iterator over letters of the alphabet in ASCII order."""
def __init__(self, start="a", end="e"):
self.next_letter = start
self.end = end
def __next__(self):
if self.next_letter == self.end:
raise StopIteration
letter = self.next_letter
self.next_letter = chr(ord(letter)+1)
return letter
# init a object of defined iteration class
>>> letter_iter = LetterIter()
>>> letter_iter.__next__()
"a"
>>> letter_iter.__next__()
"b"
>>> next(letter_iter)
"c"
>>> letter_iter.__next__()
"d"
>>> letter_iter.__next__()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "<stdin>", line 12, in next
StopIteration
如果一个对象的__iter__方法被调用后能够返回一个迭代对象,那么这个对象就是可迭代(iterable)。
>>> class Letters:
def __init__(self, start="a", end="e"):
self.start = start
self.end = end
def __iter__(self):
return LetterIter(self.start, self.end)
>>> b_to_k = Letters("b", "k")
>>> first_iterator = b_to_k.__iter__()
>>> next(first_iterator)
"b"
>>> next(first_iterator)
"c"
>>> second_iterator = iter(b_to_k)
>>> second_iterator.__next__()
"b"
>>> first_iterator.__next__()
"d"
>>> first_iterator.__next__()
"e"
>>> second_iterator.__next__()
"c"
>>> second_iterator.__next__()
"d"
for语句也可以用于列举。
for <name> in <expression>:
<suite>
编译器首先会检查<expression>是否是可迭代对象,然后调用__iter__方法。编译器会反复调用__next__方法直至遇到StopIteration。每次调用__next__方法,编译器都会把得到的值绑定在<name>上,然后执行<suite>语句。下面两个示例是等价的。
>>> counts = [1, 2, 3]
>>> for item in counts:
print(item)
1
2
3
>>> items = counts.__iter__()
>>> try:
while True:
item = items.__next__()
print(item)
except StopIteration:
pass
1
2
3
Python官网文档Iterator types一章建议迭代对象的__iter__方法最好返回迭代对象本身,这样所有迭代对象都是可迭代的。
__next__方法只能用于列举简单的迭代对象,对于复杂的迭代对象需要用到generator迭代类型。不同的是,generator迭代类型不使用return返回值,而是用yield语句。
当函数被调用时,函数体中的代码是不会运行的,函数仅仅是返回一个生成器对象。这里理解起来可能稍微有点复杂。函数中的代码每次会在for循环中被执行,接下来是最难的一部分:
for第一次调用生成器对象时,代码将会从函数的开始处运行直到遇到yield为止,然后返回此次循环的第一个值,接着循环地执行函数体,返回下一个值,直到没有值返回为止。
一旦函数运行再也没有遇到yield时,生成器就被认为是空的。
>>> def letters_generator():
current = "a"
while current <= "d":
yield current
current = chr(ord(current)+1)
>>> for letter in letters_generator():
print(letter)
a
b
c
d
>>> letters = letters_generator()
>>> type(letters)
<class "generator">
>>> letters.__next__()
"a"
>>> letters.__next__()
"b"
>>> letters.__next__()
"c"
>>> letters.__next__()
"d"
>>> letters.__next__()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
StopIteration
Python中还有Streams类可以返回数据序列。Streams实例是懒惰计算(Lazyily Computed)的。
>>> class Stream:
"""A lazily computed linked list."""
class empty:
def __repr__(self):
return "Stream.empty"
empty = empty()
def __init__(self, first, compute_rest=lambda: empty):
assert callable(compute_rest), "compute_rest must be callable."
self.first = first
self._compute_rest = compute_rest
@property
def rest(self):
"""Return the rest of the stream, computing it if necessary."""
if self._compute_rest is not None:
self._rest = self._compute_rest()
self._compute_rest = None
return self._rest
def __repr__(self):
return "Stream({0}, <...>)".format(repr(self.first))
Streams实例返回两项:first 和 rest。每次返回值时只计算first,不计算rest。
>>> r = Link(1, Link(2+3, Link(9)))
>>> s = Stream(1, lambda: Stream(2+3, lambda: Stream(9)))
>>> r.first
1
>>> s.first
1
>>> r.rest.first
5
>>> s.rest.first
5
>>> r.rest
Link(5, Link(9))
>>> s.rest
Stream(5, <...>) # rest项为None,并没有被计算出来
10 并行计算
Python有很多库可以支持并行计算。
>>> import threading
>>> def thread_hello():
other = threading.Thread(target=thread_say_hello, args=())
other.start()
thread_say_hello()
>>> def thread_say_hello():
print("hello from", threading.current_thread().name)
>>> thread_hello()
hello from Thread-1
hello from MainThread
>>> import multiprocessing
>>> def process_hello():
other = multiprocessing.Process(target=process_say_hello, args=())
other.start()
process_say_hello()
>>> def process_say_hello():
print("hello from", multiprocessing.current_process().name)
>>> process_hello()
hello from MainProcess
hello from Process-1
threading和multiprocessing库有着类似的API,但是前者只是建立单个线程,后者对多进程封装得更完善,对多核CPU的支持更好。更多可阅读Python标准库08 多线程与同步 (threading包),Python标准库10 多进程初步 (multiprocessing包),Python多进程并发(multiprocessing)
threading模块使用线程,multiprocessing使用进程。其区别不同在于,线程使用同一内存空间,而进程分配有不同的内存空间。因此进程间难以共享对象。但两个线程则有可能同时改写同一内存空间。为防止出现冲突,可以使用GIL保证不会同时执行可能冲突的线程。 更多对比
下面是一个线程冲突的实例
import threading
from time import sleep
counter = [0]
def increment():
count = counter[0]
sleep(0) # try to force a switch to the other thread
counter[0] = count + 1
other = threading.Thread(target=increment, args=())
other.start()
increment()
print("count is now: ", counter[0])
下面是执行过程:
Thread 0 Thread 1
read counter[0]: 0
read counter[0]: 0
calculate 0 + 1: 1
write 1 -> counter[0]
calculate 0 + 1: 1
write 1 -> counter[0]
结果是尽管执行了两次加法,但结果仍然是:1。
在Python中,最简单的保证数据同步的方法是使用queue模块的Queue类。
from queue import Queue
queue = Queue()
def synchronized_consume():
while True:
print("got an item:", queue.get()) # 得到对象
queue.task_done() # 队列任务结束
def synchronized_produce():
consumer = threading.Thread(target=synchronized_consume, args=())
consumer.daemon = True
consumer.start()
for i in range(10):
queue.put(i) # 加入新对象
queue.join() # 确保所有队列任务结束后,退出
synchronized_produce()
如果上面这个办法因为某些原因做不到,那我们可以使用threading模块中的Lock类。
seen = set()
seen_lock = threading.Lock()
def already_seen(item):
seen_lock.acquire() # 在Lock类的
result = True # acquire方法
if item not in seen: # 和release方法
seen.add(item) # 之间的代码仅能
result = False # 被一个线程
seen_lock.release() # 同时访问
return result
def already_seen(item):
with seen_lock:
if item not in seen:
seen.add(item)
return False
return True
还有一个办法是threading模块中的Barrier类。
counters = [0, 0]
barrier = threading.Barrier(2)
def count(thread_num, steps):
for i in range(steps):
other = counters[1 - thread_num]
barrier.wait() # wait for reads to complete
counters[thread_num] = other + 1
barrier.wait() # wait for writes to complete
def threaded_count(steps):
other = threading.Thread(target=count, args=(1, steps))
other.start()
count(0, steps)
print("counters:", counters)
threaded_count(10)
更多参考原 Python的多线程编程模块 threading 参考,17.1. threading — Thread-based parallelism。
防止共享数据错误读写的终极机制是完全避免并发地接触同一数据。进程的内存空间的独立性完全符合这一要求。为了解决进程之间的交流问题,multiprocessing模块特别提供了Pipe类。Pipe默认为两条通道,如果传入参数False则为一条通道。
def process_consume(in_pipe):
while True:
item = in_pipe.recv() # 只有接收成功后才会继续执行
if item is None:
return
print("got an item:", item)
def process_produce():
pipe = multiprocessing.Pipe(False)
consumer = multiprocessing.Process(target=process_consume, args=(pipe[0],))
consumer.start()
for i in range(10):
pipe[1].send(i) # 通过通道发送对象
pipe[1].send(None) # done signal
process_produce()
在执行并发计算时,程序员往往会犯下错误:
- 同步不足(Under-synchronization):一些线程没有被同步
- 过度同步(Over-synchronization):某些本可以并发执行的线程,被串行化
- 死锁(Deadlock):被同步的进程相互等候对方完成某些步骤才进行下一步,导致程序锁死。一个栗子:
def deadlock(in_pipe, out_pipe):
item = in_pipe.recv()
print("got an item:", item)
out_pipe.send(item + 1)
def create_deadlock():
pipe = multiprocessing.Pipe()
other = multiprocessing.Process(target=deadlock, args=(pipe[0], pipe[1]))
other.start()
deadlock(pipe[1], pipe[0])
create_deadlock()